系統設計能力是優秀工程師與普通工程師的分水嶺,能寫程式的人很多,但能設計穩健且可擴展系統的並不多,代表能掌握系統設計就能掌握偉大的航道
Introduction
定義甚麼是系統設計
系統設計本質上是大規模問題的解決藝術,在有限的成本下,運用宏觀架構思維建構系統藍圖,以當下最適合的情況在Consistency(一致性)、Availability(可用性)、以及 Partition Tolerance(分區容錯性)做出系統設計的決策。
系統設計面試逐步指南 (System Design interview Step-by-Step)
定義功能性需求 (Functional Requirements)
先列出「使用者可以做什麼」,不必窮舉所有細節,重點覆蓋最核心的幾項即可,例如:
- 使用者可以發布貼文
- 使用者可以追蹤其他用戶
- 使用者可以按讚貼文
定義非功能性需求 (Non-Functional Requirements)
性能(Latency/Performance):系統需要多快的響應?,例如頁面載入應在幾百毫秒內完成
可用性(Availability):系統需多穩定?例如要求接近 99.9% 上線時間
可擴展性(Scalability):系統能否隨用戶數或流量增加而擴充而不降低性能?例如考慮到採用垂直擴容(加強單機)或水平擴容(增加機器節點)
可靠性(Reliability):系統對故障的容忍度如何?例如確保部分服務崩潰時仍繼續提供服務
一致性(Consistency):在分散式環境中,如何保證所有用戶看到的資料同步且正確?例如加強在多資料庫或快取佈局下的策略
持久性(Durability):資料如何安全存儲以防丟失?例如確保資料寫入後不會因硬體故障而遺失
安全性(Security):如何防止未經授權的訪問或攻擊?例如需保護敏感用戶資料
API 設計 (API Design)
- 本項目主要就是將功能性需求轉化為對外提供的 API 介面,方法很簡單,一項功能對應一個端點 有三點很重要:
- 端點命名清晰:「發推文」功能用POST /tweet明確表示,優於用模糊的 POST /item 等名稱
- 資料格式明確: 道每個 API 輸入和輸出的資料是什麼類型及結構。例:發佈推文 API 的請求需包含使用者ID(字串)和推文內容(字串);回應回傳推文ID(字串)和狀態
高層次設計 (High-Level Design)
這是系統設計面試中最重要的環節,需要根據先前列出的需求繪製系統架構圖,展示服務如何協同工作。
滿足功能性需求
先設計一個最基本可行的系統來滿足功能性需求,不急著引入複雜元件
一個有效的方法是:按照每個 API/功能規劃對應的服務和資料流
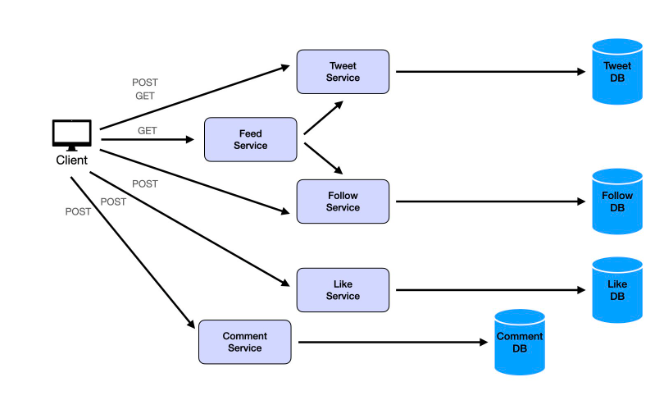
考量到切的服務數量太多了,雖然關注點分離很重要,但我們不想過度,把所有服務都變成微服務。我們需要考慮的一件事是,有沒有辦法合併一些服務?在這種情況下,我認為點讚和評論在邏輯上非常相似,我們把它合併,通常會加上一個API Gateway作為統一入口。
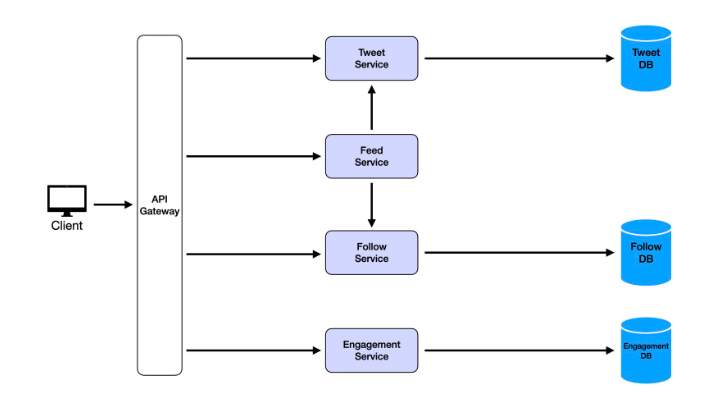
滿足非功能性需求
水平擴展與負載均衡:為提升可擴展性,將每個服務部署多個實例,並在前方加上負載均衡器 (Load Balancer) 來分配流量,同時負載均衡器也能透過健康檢查移除故障節點,提升高可用性。
引入快取:為確保低延遲(性能),在關鍵讀取路徑上增加緩存層 例如 Feed Service 可以使用分散式快取(如 Redis/Memcached)來存放每個用戶近期的推文動態 寫入新推文時,預先將其推送到關注者的快取中(預計算 feed),讓讀取請求直接從快取獲取「熱資料」
加入消息隊列:在關鍵的跨服務操作間使用消息佇列 (Message Queue) 作為緩衝 例如在 Twitter 案例中,用戶發推文時 Tweet Service 並不直接同步更新 Feed Service,改為將新推文資訊放入隊列,由後臺消費者異步地從隊列讀取消息,更新資料庫和快取
- 這樣即使某服務當機,消息也不會遺失,稍後可繼續處理,確保一致性
- 消息隊列還能削峰填谷,吸收瞬時的大量請求,防止高峰流量把系統壓垮,確保可靠性
使用分散式資料庫:為保障資料耐久性和高可用,將單節點資料庫升級為分散式資料庫集群 透過多節點資料複寫,即使一臺資料庫機器故障,資料也可從其他節點獲取,不會遺失 例如可採用 Cassandra、Amazon DynamoDB 或 Google Spanner 等支援自動複寫與備份的分散式資料庫
深度探討 (Deep Dives):
檢驗你對系統設計細節和權衡取捨的理解程度,為前一章節高層次設計 (High-Level Design)的Follow-Up,
「名人用戶」問題:當一個擁有數百萬追隨者的用戶發佈內容時,需要將該內容推送到數以百萬計的粉絲時間線,這會產生巨大的扇出負載,可能拖垮系統 解決方案:對一般用戶維持既有的寫入時廣播(fan-out-on-write,即發佈時即刻推送給所有粉絲);但對超大量粉絲的名人帳戶改用讀取時廣播(fan-out-on-read),當粉絲打開動態時,再即時從快取/資料庫提取名人最新推文合併顯示 可設定一個門檻(例如粉絲數超過某值)動態判定對某用戶採用哪種模型
「趨勢標籤」問題:例如 Twitter 的熱搜趨勢/主題標籤功能,需要即時地從全球數十億推文中統計熱門話題 解決方案:採用分散式聚合計算和索引相結合的方案 首先在每個地區的伺服器上本地計算該區域短時間窗口(如過去15分鐘)內的熱門話題,然後將區域結果發送到中央的全域聚合服務合併計算出全球趨勢 同時,在推文發佈時即更新倒排索引(例如使用 Elasticsearch 等搜尋引擎)來記錄每個主題標籤關聯的推文ID清單,方便快速查詢熱門標籤下的內容 快取計算結果,並設定短TTL,使趨勢榜單每隔比如1分鐘更新,同時避免過度頻繁的重算
「搜尋服務擴展」問題:提供即時、全站的推文搜尋功能需要特殊設計 解決方案:引入分散式搜尋架構 新推文產生時透過消息隊列發送給搜尋索引服務,將內容即刻索引至後端的搜尋引擎(如 Elasticsearch 或 Solr) 為了應對龐大的資料量,將索引按時間或主題切分分片,分散存儲在多個節點上(舊資料索引可放在較慢存儲,以節省成本,新近資料在高速節點) 查詢時使用倒排索引技術高效匹配關鍵字,並實施結果排序演算法(例如 BM25 或機器學習排序)以提升相關性 對於高頻重複的搜尋請求,可將結果緩存在快取中,減輕後端負荷
1️. 引入分散式搜尋架構 使用 Elasticsearch 或 Solr 等搜尋引擎 + 多台機器分工 → 這些系統可以讓大量資料被分散存放在不同節點上,同時支援關鍵字搜尋。
2️. 新推文產生時,用消息佇列通知搜尋服務進行索引 推文一發佈,先丟到消息隊列(像 Kafka)→ 搜尋服務收到後立即索引 → 好處是非同步、高效能、可擴充:你不會在發文時就卡住等待搜尋引擎處理。
- 索引切分與節點分佈 根據時間或主題把索引拆成分片(shard)分散在多台機器 → 範例:
2024年6月的推文 → 存在 shard A
2024年7月的推文 → 存在 shard B 這樣可以分散壓力與加速搜尋效率。
舊資料存在較慢的機器,新資料放在快的節點 → 節省成本:因為用戶大多搜尋近期推文,老資料查不到也沒那麼要緊。
- 查詢時使用倒排索引技術 倒排索引(Inverted Index):快速找出「哪篇文章包含這個關鍵字」 → 舉例:
“狗”: [文章1, 文章5, 文章9] “貓”: [文章2, 文章5] → 這是搜尋引擎最常用的資料結構,可以快速定位內容。
BM25 / ML 排序模型:提升搜尋結果的「相關性」 → 不是只有包含關鍵字就好,還要依照字詞出現次數、位置、重要程度排序結果 → 或用機器學習預測哪些結果最可能是使用者要的。
- 高頻重複查詢的快取策略 例如:很多人一直搜尋「地震」 → 結果先快取起來,下次直接從 Redis 拿,不必重查後端,提高效率。
- 整體意思整理成一句話: 為了讓使用者能即時搜尋數億筆推文,我們要把資料「分片 + 分布式儲存」,新資料即時索引、查詢用倒排索引技術找關鍵字、熱門查詢再快取起來,整體系統才能又快又穩地撐住高流量。
核心設計挑戰 (Core Design Challenges)
設計大規模系統時,有幾類常見的架構難題反覆出現。下面列出最典型的幾項:
挑戰1: 並發使用者過多 – 單台機器(或單一資料庫)能處理的每秒請求量是有限的,如果同時在線用戶暴增,單機系統性能很快就會崩潰 解決方案:水平擴展 (Scale-Out),也就是資源複製 將應用部署到多台伺服器上,並使用負載平衡將用戶請求分散到不同實例,避免單點過載。同時,資料庫也採用主從複製或叢集,讓多個資料庫節點分擔查詢流量
挑戰2: 數據量過於龐大 – 當資料成長到無法放入單台機器的程度(所謂「大資料」),需要考慮資料存儲和訪問的分散化 解決方案:資料分片 (Sharding) 按照某種邏輯(例如用戶ID、地區等)將資料劃分到多個節點上存儲。每個分片只包含整體資料的一部分,
系統需保持高速響應 – 大多數面向用戶的應用都要求響應迅速,通常希望請求處理在數百毫秒內完成;超過1秒用戶體驗就顯著下降 問題所在:讀取操作通常可透過讀取副本和快取實現快速返回,但寫入操作往往涉及多步資料庫查詢和更新,處理時間可能遠超過1秒 解決方案:非同步處理 (Asynchrony) 也就是在接收到寫請求時,立即返回確認(將任務放入佇列),而實際繁重的處理在後端排程執行 例如用戶提交一筆資料後,伺服器先同步返回一個接受狀態,然後將該請求放入後台的消息隊列,由工作線程稍後完成實際的資料庫寫入等操作。同時前端可先行顯示部分結果或過渡UI,掩蓋後端處理時間
挑戰4: 數據不一致(舊資料) – 解決前兩項挑戰(引入資料複製和非同步更新)後,新的問題是資料的一致性:由於讀寫分離和延遲更新,使用者可能短暫讀到過期的舊資料 通常這不會導致亂七八糟的錯誤資料,只是舊的或已刪除的版本而已 解決方案:最終一致性 (Eventual Consistency) 在許多應用中,我們可以容忍資料在短時間內不同步,只要最終能趕上正確狀態即可。因此側重於應用層解決:設計用戶體驗時允許數據短暫不同步而不影響整體功能。隨著後端最終完成同步,前端資料會自動更新到最新。
規模化設計 (Designing for Scale)
為了滿足上述非功能性需求,系統架構需要考慮可擴展性 (Scalability)。
功能分解 (Decomposition):將大型單體應用拆分成微服務 (Microservices),每個服務各司其職,處理特定的業務能力 通過將系統切分為小而獨立的服務,可以讓各部分獨立部署與擴展,也降低了理解和維護的複雜度
垂直擴展 (Vertical Scaling):提升單台伺服器的性能,俗稱「加大機器」 具體做法是使用更強大的硬體(更快的CPU、更多記憶體等)來支撐更高負載。
水平擴展 (Horizontal Scaling):透過增加更多相同的服務實例來擴大容量,即所謂「擴容」 通常要求服務是無狀態 (stateless)的,這樣任何節點都可處理任何請求。利用負載平衡器將請求平均分配到各節點,可以輕易通過加機器來提高系統吞吐。
資料分區 (Partitioning/Sharding):將資料和請求拆分,分散到多個資料庫或服務上處理 常見方式是根據某鍵值(如用戶ID、地理位置)對資料進行邏輯分組,不同分組由不同節點處理 這可大幅減小單節點的資料量和負載,並允許分片並行處理請求。如前述的Sharding範例,把 Twitter 用戶依ID哈希到不同資料庫,即是典型的資料分區策略 實作時需考慮均衡分片(例如一致性哈希確保資料平均分佈)以及路由機制(將請求導向正確分片)。
快取 (Caching):利用記憶體快取來保存常用的熱門資料,以提升讀取效能 當大量重複讀取相同資料時,快取(如 Redis、Memcached)可以在內存中提供高速存取,避免每次都訪問慢速的後端資料庫 同時需設計失效策略(TTL或更新機制)確保快取不會長期存放過期資料
寫入緩衝 (Buffering with Message Queues):當系統寫入頻繁且尖峰併發很高時,大量同步直寫資料庫會因磁碟I/O瓶頸而拖慢或擊潰系統 解決方法是引入消息隊列作為緩衝,將同步寫入改為異步 前端請求先寫入隊列,即刻返回成功,後端消費者再從隊列批量讀取進行資料庫實際寫入
讀寫分離 (Separating Read and Write):根據業務性質區分處理讀多寫少或寫多讀少的場景,以最佳化各自性能 典型做法是主從資料庫架構:所有寫操作發往主庫,再異步複製到多個從庫供讀操作查詢,從而隔離讀寫負載並提升讀取併發能力 進階一點的是 CQRS (Command Query Responsibility Segregation) 模式:將寫入與讀取使用完全不同的資料模型和存儲 寫入端(命令端)專用一套資料庫處理交易,讀取端(查詢端)使用預先整理好的去正規化資料(甚至使用不同類型的數據存儲如搜尋引擎)來快讀。兩端的資料透過異步流程保持同步
一句話 => 實際系統設計往往需要多種擴展手段配合 例如先透過微服務分解減少耦合,再結合資料分片與快取來同時解決資料量和存取速度問題,並應用讀寫分離確保寫入可靠與讀取快速
通用模板 (Master Template)
這是一個適用於大多數大規模系統的通用高效架構模板。掌握此模板,有助於你在面試中快速構思穩健的設計方案。
無狀態服務 (Stateless Services):前端請求先經過負載平衡器分配給後端服務節點處理 服務本身不保存用戶狀態,以便任意擴增實例數目而不影響會話。常見做法是區分寫服務與讀服務:前者專門處理客戶端寫入請求,後者專門處理讀取請求,
資料庫 (Database):作為冷資料存儲和最終權威數據源 在高併發場景下,我們不直接從資料庫讀取每次請求所需資料,而是更多地依賴快取(資料庫更像最後備份及批量讀取時使用)。
消息佇列 (Message Queue):扮演寫入緩衝區的角色,位於寫入服務和資料存儲層之間 當前端有寫入操作時,寫服務將請求內容封裝成消息放入隊列,然後即刻返回成功響應給用戶 佇列的存在將生產者(寫服務)與消費者(後端處理)解耦: 生產者 (Producers):通常是前述的寫服務,它們將資料變更以消息形式推送進隊列
消費者 (Consumers):後端啟動的工作線程/服務,從隊列中讀取消息並執行實際處理 通常我們啟動兩類消費者:一種專門負責更新資料庫(將消息寫入永久存儲) systemdesignschool.io ;另一種負責更新快取(將最新資料寫入緩存,以供讀服務快速訪問)
快取 (Cache):作為快速讀取層,存放經常查詢的資料 快取通常位於記憶體中,訪問延遲遠低於直接查詢資料庫。對於高頻讀取需求,讀服務會優先從快取獲取資料 快取中的資料由後台消費者異步維護:定期或透過事件將資料庫更新內容同步到快取,確保快取逐步趨於最新
為何需要消息佇列:
調節生產-消費速率差:前端請求和後端處理能力經常不對等。佇列充當緩衝,允許前端高速產生請求,同時後端按自身節奏處理 例如
故障隔離與資料保護:透過將請求持久化在隊列中,即使後端消費者暫時掛掉或重啟,也不會遺失未處理的消息 假如沒有隊列,寫服務直接呼叫資料庫更新,萬一資料庫當下不可用,那麼該請求就直接失敗且資料丟失。而引入隊列後,請求會先記錄下來,後端恢復時繼續處理,提高了容錯性
一句話:其核心理念可總結為:「寫入經由消息隊列,再由消費者/工作者更新資料庫和快取;讀取直接從快取獲取」
# NoSQL vs RDBMS
NoSQL vs RDBMS 初言
「我會先確認資料*結構*、*一致性需求*、*讀寫模式*、*擴充性*與*營運成本*,然後再決定用關聯式或 NoSQL——通常不是技術先行,而是需求先行。」
我們可以起初為主要功能各建立一個簡單服務:Tweet Service(處理發文)、Feed Service(處理動態閲讀)、Follow Service(處理關注關係)、Engagement Service(處理點讚和評論)、User Service(處理用戶資料) 每個服務有各自的數據存儲(資料庫)以保存相關資訊。
RDBMS
關聯度高 + 交易嚴謹 + SQL 報表
關鍵需求 說明 常見案例 ACID 交易 需要強一致性、多表交易、Roll-back 金流、訂單、庫存扣帳 複雜查詢 / JOIN 跨表關聯、多維統計報表 ERP、CRM、商業分析 結構穩定 Schema 變動少、嚴格型別 企業主資料、權限模型 成熟生態 SQL 標準、OLAP、工具支援 BI 報表、ETL 流程
→ 一句總結:「當資料結構規範、交易一致性和 JOIN 很重要時,用 RDBMS。」
NoSQL
Schema 彈性 + 高寫入 + 水平擴充
NoSQL 類型 關鍵優點 適用情境 Key-Value / Cache(Redis、DynamoDB) 亞毫秒延遲,水平擴充方便 Session、排行榜、快取 Document(MongoDB) 彈性 Schema、JSON 原生 商品目錄、使用者設定 Wide-Column(Cassandra、HBase) 高寫入量、時間序列良好 物聯網遙測、即時 log Graph(Neo4j、JanusGraph) 關係遍歷效率高 社群關係、推薦系統
一句總結:「當資料格式多變、寫入量爆炸或要全球分區水平擴充時,用 NoSQL。」
Polyglot Persistence 實務模型
「關聯多、錢要準 → Postgres;格式亂、量要撐 → Mongo。」
「實務上很多系統會並存:交易核心放 RDBMS,旁邊再用 Redis 做快取、用 Elasticsearch 做全文檢索;這樣既保 ACID,又兼顧讀寫性能與搜尋體驗。」
NoSQL vs RDBMS 結論
RDBMS: 強一致、多表交易、複雜 JOIN,金融訂單最典型。 NoSQL: 彈性 Schema、水平擴充、低延遲,大流量記錄或快取最適合。 實務: 常混用,核心 ACID 放 RDBMS,其餘讀多寫多放 NoSQL/Cache。
「所以我會先確認系統對 一致性 vs. 可用性 的容忍度、資料模型複雜度、以及未來流量成長方向,再決定單一或混合使用關聯式與 NoSQL。」
Sharding vs. Partition
Sharding vs. Partition(一分鐘速懂) Partition(分區) Sharding(分片/分庫分表)
Partition: 把一張表切成多塊資料區,仍由 同一個資料庫執行個體 管理 Sharding: 把資料切到多台伺服器或多個 DB 叢集,每台只管自己的那一塊
- 目的 ▸ 提高單機 I/O 與查詢效率 ▸ 方便歸檔、維護、清理 ▸ 水平擴充容量與吞吐量 ▸ 分散單點風險、支援跨區部署
典型做法 - PostgreSQL Declarative Partition
- MySQL RANGE / LIST Partition
- Oracle Partition Table - MongoDB Sharding
- Cassandra / HBase Ring
- MySQL Vitess、TiDB、CockroachDB
情境
Partition:單機已能承受流量,只是表太大、查詢掃描慢,按日期或 ID 區間切分,加區域索引即可 Sharding:單機 CPU/IO/記憶體到極限,還要繼續長大,或需跨洲部署,把資料水平切到多節點,支撐更多 QPS
一句結論 =>
- Partition 解決「單機內部資料太大」;
- Sharding 解決「單機再大也容不下」與「地理分佈」的需求。
先判斷瓶頸在容量還是節點,再決定用哪一招。
CREATE TABLE orders (
id BIGINT,
created_at DATE,
total NUMERIC
) PARTITION BY RANGE (created_at);
CREATE TABLE orders_2025_06 PARTITION OF orders
FOR VALUES FROM ('2025-06-01') TO ('2025-07-01');
# 命中單一,Explain 只是用來檢查與示範執行計畫
EXPLAIN (ANALYZE, VERBOSE)
SELECT id, total
FROM orders
WHERE created_at >= DATE '2025-06-01'
AND created_at < DATE '2025-07-01';
SELECT * FROM orders_2025_06 WHERE id = 42;
PostgreSQL:created_at BETWEEN '2025-06-01' AND '2025-06-30'
sh.enableSharding("ecommerce");
db.orders.createIndex({ userId: "hashed" });
sh.shardCollection("ecommerce.orders", { userId: "hashed" });
# 命中單一分片的查詢
db.orders.find({ userId: NumberLong("9988") })
.explain("executionStats");
一句話 => 掌握「直接比分區鍵 + 等值或明確範圍」這一點,就能寫出高效率、只打到目標分片/分區的查詢。
