LeetCode作為一個線上編程競賽與刷題平台,需要提供題目瀏覽、程式碼提交與評測以及競賽排行榜等功能,今天來學怎麼設計LeetCode平台!
Introduction
- 首先來介紹LeetCode的主要功能:
- 查看問題:使用者應該能夠查看問題描述、範例、約束並瀏覽問題清單。
- 提交解決方案:使用者應該能夠透過提交他們的解決方案程式碼並針對內建測試案例運行它來獲得結果,從而解決編碼問題。
- 程式設計競賽:使用者可以參加程式設計競賽。競賽為限時活動,固定時長2小時,包含4題目。得分根據解答題目數量和解答時間計算。結果將會即時顯示。排行榜將顯示排名前50的用戶及其用戶名和得分。
- 規模要求:
- 支援1萬用戶同時參與比賽。
- 每天最多有一場比賽。
- 每場比賽持續2小時。
- 每位使用者平均提交 20 次解決方案。
- 每次提交平均執行 20 個測試案例。
- 用戶提交的代碼有 1 個月的保留策略,之後將被刪除。
- 假設每個編碼問題的解答所需的儲存空間為10KB。
- 假設讀寫比為2:1。
- 在設計LeetCode主要會遇到的挑戰:
- 高並發(例如同時有一萬名用戶參賽提交程式碼)
- 即時的資料更新(如每秒多次更新排行榜)
- 執行用戶不受信任的程式碼時的安全隔離
- 解決方案:
- 微服務架構
- 訊息佇列(Message Queue)
- 容器沙盒(Docker Sandbox)
開始設計LeetCode
Step1 - 定義非功能性需求
- 非功能性需求
- 高可用性:網站應全天候訪問
- 高可擴充性:網站應該能夠處理 10,000 名使用者同時提交程式碼
- 低延遲:比賽期間,排行榜應即時更新
- 安全性:使用者代碼無法破解伺服器
Step2 - 定義API端點
GET /problems?start={start}&end={end} Get problems in a range. If start and end are not provided, get all problems with default page size.
Response Body:
{
problems: [
{ id: string, title: string, difficulty: string }
]
}
GET /problems/:problem_id Get problem details, including description, constraints, examples, and starter code.
Response Body:
{
id: string
title: string
difficulty: string
description: string
constraints: string
examples: [{
input: string
output: string
}]
starter_code: {
language: string
code: string
}
}
POST /problems/:problem_id/submission Submit code for a problem and get results.
Request Body:
{
user_id: string
code: string
language: string
}
Response Body:
{
status: success | fail
test_cases: [
{ status: success | fail | timeout }
]
}
GET /contests/:contest_id/leaderboard Get leaderboard for a contest.
Response Body:
{
ranking: [
{ user_id: string, score: number }
]
}
Step3 - High Level Design
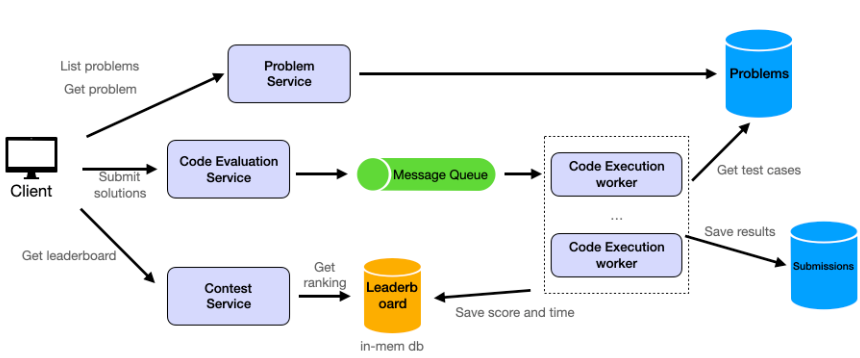
- 以微服務的角度,來系統設計,把所有功能都抽成小元件
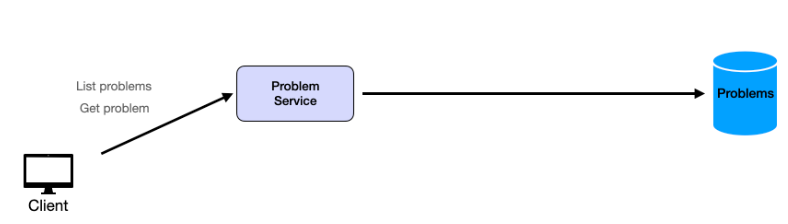
檢視問題元件
採用系統設計中標準的三層架構:
- 客戶端:發送 HTTP GET 請求的前端應用程式
- 問題服務:帶有端點的後端服務: GET /problems?start={start}&end={end}:列出問題 GET /problems/:problem_id:獲取具體問題的詳細信息
- 資料庫:儲存問題資料(ID、標題、描述、難度、範例、限制)
提交問題元件
在設計我們類似 LeetCode 平台的程式碼評估流程時,我們需要考慮10,000 名使用者同時參與比賽的高並發需求,平均每位使用者提交約 20 次解決方案。這是我們設計模板的典型用例。
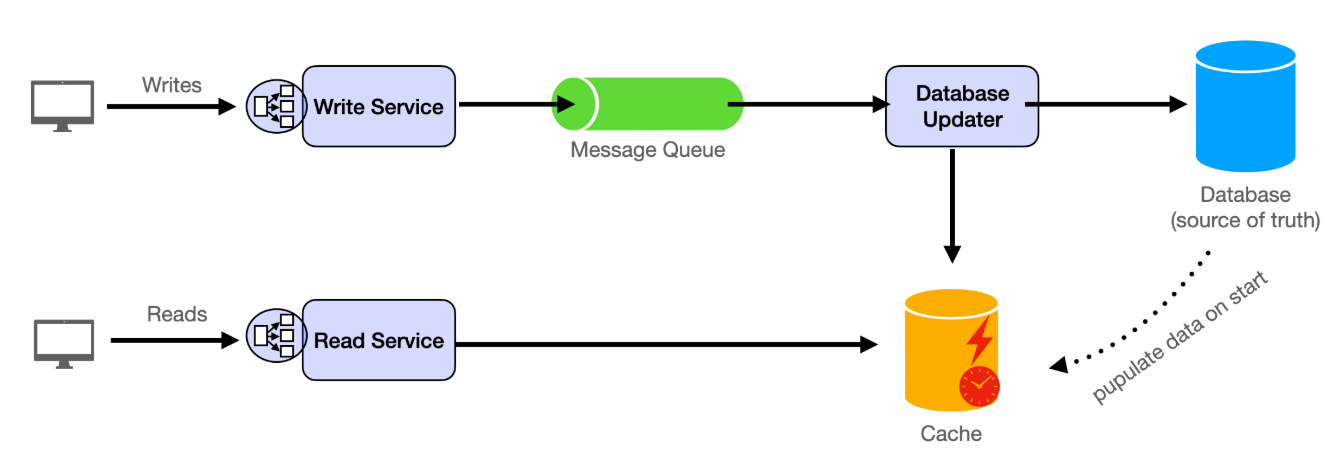
我們使用代碼評估服務作為代碼提交的入口。該服務負責接收用戶的程式碼並啟動評估流程。為了有效率且安全地處理大量提交,我們引入了訊息佇列作為提交流程和實際程式碼執行之間的緩衝區。程式碼提交的計算量可能很大,我們不希望在處理大量提交時導致整個服務癱瘓。因此,我們選擇將這兩個服務分開。
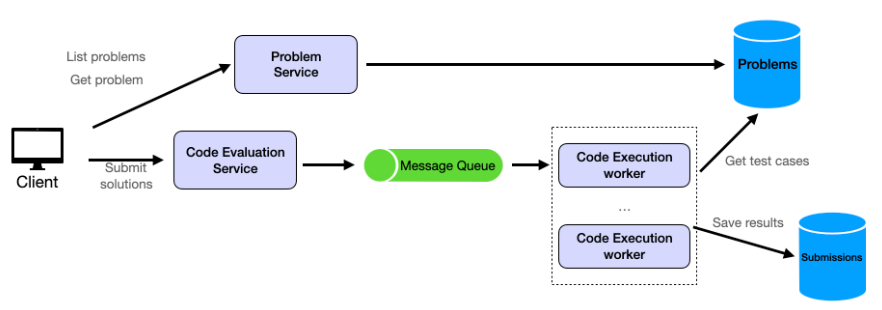 在訊息佇列的另一端,我們有多個程式碼執行工作器。這些工作器會持續輪詢隊列,尋找新的提交。收到訊息後,它們會從問題資料庫中提取必要的測試案例,在沙盒環境中執行程式碼,並記錄結果。
在訊息佇列的另一端,我們有多個程式碼執行工作器。這些工作器會持續輪詢隊列,尋找新的提交。收到訊息後,它們會從問題資料庫中提取必要的測試案例,在沙盒環境中執行程式碼,並記錄結果。
沙盒環境要使用哪種執行環境
- A. API 伺服器 - 不宜直接在 API 伺服器上執行
工作原理: 使用者提交的程式碼直接在託管 API 的伺服器上執行。程式碼通常以檔案形式保存在伺服器的檔案系統上,然後使用相應的解釋器或編譯器執行。
優點:
- 易於實現,由於 API 和程式碼執行之間沒有額外的層,因此延遲較低 缺點:
- 嚴重的安全風險:惡意程式碼可能會存取或修改伺服器數據
- 隔離性差:使用者程式碼中的一個錯誤可能會導致整個伺服器崩潰
- 資源管理問題:一個使用者的程式碼可能會消耗所有伺服器資源 結論: 不適合運行用戶提交的程式碼。安全性和穩定性風險遠大於其簡單性所帶來的好處。
- B. 虛擬機器(VM)- 適用但有警告
工作原理: 每次程式碼執行都會虛擬化一個完整的作業系統。使用者程式碼在這個模擬專用硬體的隔離環境中運作。
優點:
- 強隔離:每個執行環境完全獨立
- 靈活:可以運行任何作業系統或配置
- 安全性高:虛擬機器對主機系統的存取有限 缺點:
- 資源密集:每個虛擬機器都需要大量的 CPU、記憶體和儲存空間
- 啟動緩慢:啟動完整的作業系統需要時間
- 管理複雜:需要虛擬化技術的專業知識 結論: 適合,但對於簡單的程式碼執行來說可能有點過頭了。最適合需要完全作業系統隔離或特定作業系統環境的場景。
- C. 容器(Docker) 非常適合 - 輕量級、隔離的執行環境
工作原理: 容器將程式碼及其相依性打包在一起。它們共享主機作業系統內核,但在隔離的用戶空間中運行,從而提供輕量級、一致的環境。
優點:
- 高效率的資源利用:比虛擬機器更輕,允許更多並發執行
- 快速啟動:容器可在幾秒鐘內啟動
- 一致的環境:確保程式碼在開發和生產過程中以相同的方式運行
- 良好的隔離:一個容器中的程序不能直接影響其他容器 缺點:
- 隔離性比虛擬機器低:所有容器共享主機作業系統內核
- 如果配置不正確,可能會出現安全性問題
- 容器技術的學習曲線 結論: 非常適合此用例。在安全性、效能和資源效率之間實現了良好的平衡。
- D. 無伺服器函數 - 合適的
工作原理: 事件驅動、自動擴充程式碼執行,程式碼以函數形式部署到雲端提供者。提供者管理執行環境,並根據需要自動擴展資源。函數是無狀態的,並且由事件驅動。
優點:
- 高度可擴展:自動處理不同的負載
- 經濟高效:僅按實際使用的計算時間付費
- 維護成本低:供應商管理基礎設施
- 隔離性好:每個函數執行都是獨立的 缺點:
- 冷啟動延遲:不常用的功能可能會延遲啟動
- 執行時間有限:大多數提供者都有最大運行時間限制
- 潛在的供應商鎖定:可能與特定的雲端供應商服務相關 結論: 尤其適用於負載變化較大或需要關注基礎設施管理的場景。非常適合短時間運行、無狀態的程式碼執行。
我們將選擇容器(Docker)而不是無伺服器功能,以獲得更快的啟動時間和更少的供應商鎖定。
為了確保安全性和隔離性,每個提交都在單獨的容器中運行,以防止惡意程式碼影響我們的系統或其他使用者的提交。我們可以利用Docker等技術來實現此目的。
執行後,結果(包括程式碼是否通過所有測試案例、執行時間和記憶體使用情況)會保存在 Submissions 表中。
為何不改用 WebSocket/SSE?
WebSocket 對於簡單的狀態更新來說有些過度了。它是為雙向即時通訊而設計的,但我們只需要以可預測的間隔進行單向狀態更新。
SSE 仍然需要保持長期 HTTP 連線開放,這在比賽期間管理數千個並髮用戶時可能會佔用大量資源。
由於輪詢負載是可預測的(提交後,前端僅在等待結果時每 1-2 秒輪詢一次),因此即時連接的額外複雜性是沒有意義的。簡單的 HTTP 輪詢可以提供足夠的使用者體驗,同時更易於實現。
程式設計競賽元件
用戶可以參加程式設計競賽。競賽為限時活動,固定時長為 2 小時,包含 4 題目。得分根據解答題目數量和解答時間計算。結果將會即時顯示。排行榜將顯示排名前 50 名的用戶及其用戶名和得分。
我們可以使用一個集中式服務來管理競賽,也就是程式設計競賽元件。用戶提交解決方案後,代碼評估服務會對其進行評分,並將使用者的分數記錄到資料庫中。
這裡的關鍵在於將比賽數據、用戶得分和排行榜儲存在何處。我們需要即時更新排行榜,而且數據經常變化。我們可以使用像 Redis 這樣的記憶體資料庫來儲存排行榜。
如何實現Redis一個支援即時Top N查詢的排行榜?
- 比較各個Redis替代方案
- A Redis - 非常適合內存資料結構存儲,使用 ZSET 作為排行榜
工作原理: 使用有序集合資料結構來維護分數。每個使用者都是集合中的成員,並以他們的分數作為排序標準。
優點:
- 極快的讀寫操作
- 內建排名和範圍查詢
- 可擴展並能處理高並發性 缺點:
- 資料易失性(記憶體中),需要持久化策略
- 可能需要額外的基礎設施設置 結論: 非常適合頻繁更新和查詢的即時排行榜。
- 有序集合的內部實作為一個哈希表和一個跳躍表。哈希表儲存了使用者 ID 和分數之間的映射關係。跳躍表則保持分數依升序排列。 跳躍表是一系列帶有指向中間節點的附加指標的連結列表,可實現高效的遍歷和搜尋操作。
為了獲取排行榜,即獲取排名靠前的N用戶,我們可以下到第 0 級並找到列表中的最後一個元素,然後執行向後迭代以獲取排名靠前的N用戶(跳躍表中的鍊錶是雙向鏈接的)。
在 Redis 中,這實現為ZSET。我們使用ZADD來添加用戶及其分數,並使用ZRANGE來獲取排名靠前的N用戶。
- B NoSQL資料庫 - 適用但有警告,基於文件的儲存(例如 MongoDB)
工作原理: 將使用者得分儲存為文件。使用得分欄位的索引和特定於資料庫的查詢來執行排行榜操作。
優點:
- 良好的可擴展性
- 靈活的模式
- 可以處理大量數據 缺點:
- 最終一致(可能不適合即時更新)
- 與 SQL 相比,查詢可能更複雜 結論: 適用於可接受最終一致性的大規模排行榜。非常適合需要靈活資料模型的場景。
- C 記憶體資料結構 (In-Memory Data Structure) - 適用但有警告,使用堆或類似結構的自訂實現
工作原理: 在應用程式記憶體中維護堆或類似的資料結構來追蹤最高分數。
優點:
- 內存操作非常快
- 易於實現
- 無需額外的基礎設施 缺點:
- 受可用記憶體限制
- 持久性需要額外的機制
- 對於分散式系統可能無法很好地擴展 結論: 適用於小型應用或作為大型系統的一部分。不適用於大型分散式排行榜。
- D 時間序列資料庫 (Time-Series Database) - 不宜,基於時間的資料的專用資料庫(例如,InfluxDB)
工作原理: 將分數儲存為時間序列資料點。使用基於時間的查詢來檢索最新分數和排名。
優點:
- 針對基於時間的數據進行了最佳化
- 適合歷史分析和趨勢分析
- 有效率地進行時間範圍查詢 缺點:
- 如果你不需要歷史數據,可能會有點過度
- 可能更複雜的設置
- 未針對相同數據點的頻繁更新進行最佳化 結論: 適用於需要歷史追蹤或基於時間分析的排行榜。對於簡單的排行榜需求來說,可能過於複雜。
我們希望使用像 Redis 這樣的記憶體資料庫,因為它更新非常頻繁,而且較舊的資料可以被丟棄。 Redis 實際上內建了一個排行榜實現。它背後的資料結構是有序集合(ZSET)。有序集合將唯一元素(成員)與分數組合在一起,並自動保持元素按分數排序。
後續Follow-Up
沙盒環境系統安全
如何保證程式碼執行的安全性和隔離性?
在容器等沙盒環境中運行程式碼已經提供了一定程度的安全性和隔離性。我們可以透過限制每次程式碼執行可使用的資源(例如 CPU、記憶體和磁碟 I/O)來進一步增強安全性。我們也可以使用類似技術seccomp來進一步限製程式碼可以進行的系統呼叫。
具體來說,為了防止惡意程式碼影響其他使用者的提交,我們可以使用以下技術:
- 資源限制:限制每個程式碼執行可以使用的資源,例如 CPU、記憶體和磁碟 I/O。
- 時間限制:限制每次程式碼執行的執行時間。
- 系統呼叫限制:使用類似的技術’seccomp’來限製程式碼可以進行的系統呼叫。
- 使用者隔離:在單獨的容器中執行每個使用者的程式碼。
- 網路隔離:限制每個程式碼執行的網路存取。
- 檔案系統隔離:限制每個程式碼執行的檔案系統存取。
如何處理大量參賽者同時提交解決方案?
處理大量參賽者同時提交的解決方案會帶來許多挑戰,尤其是在比賽開始和結束這樣的高峰時段。我們可以採用兩階段處理方法並結合其他策略來解決這個問題:
訊息佇列:使用訊息佇列將提交過程與執行過程解耦。這使我們能夠在高峰時段緩衝提交,並在資源可用時進行處理。
預先擴展:由於自動擴展的速度可能不足以應對突發峰值,請在比賽開始前預先擴展執行伺服器。這對於比賽的前10分鐘和最後10分鐘尤其重要,因為這兩個時間段提交率通常最高。
- 兩階段處理:
第一階段(比賽進行中): 對每份提交只執行部分測試案例(例如僅10%)這樣可以迅速給出初步判定(通過或失敗),並更新臨時排行榜,讓用戶及時獲得反饋。由於只跑少量測試,每次提交耗時大幅縮短,系統吞吐量提高,可應對極端並發。
第二階段(比賽結束後): 對所有提交進行完整測試(剩餘90%案例)。以完整結果計算最終得分並更新最終排行榜。若最終結果與臨時結果有差異(例如某提交在完整測試時未通過某些隱藏測資),則排行榜名次可能略有變動。這種權衡允許系統在比賽期間降低負載,而在比賽結束後花額外時間完成最終評測。
減少比賽期間的系統負荷。可以獲得更準確的最終結果。與 Codeforces 等平台在大型競賽中採用的方法類似。 這種方法能夠有效率地利用資源,為使用者提供即時回饋。雖然這意味著比賽結束後無法立即獲得最終結果,但它能夠利用現有資源處理更多並發提交。對於大規模程式設計競賽來說,即時完整結果和系統可擴展性之間的權衡往往至關重要。
