URL Shortener是一種服務,它會將長 URL 轉生成一個短網址,並將使用者重新導向到原始 URL。
功能性需求 (Functional Requirements)
基本要求
- URL 縮短服務:使用者可以提供一個長網址,系統會回傳一個獨一無二的短網址代碼(由英文字母和數字組成),以節省空間並確保短碼的唯一性
- 短網址導向:當使用者點擊或輸入短網址後,服務需立刻將其重導向到原始長網址,過程應幾乎無延遲,確保無縫的使用體驗
- 連結點擊分析:系統應記錄每個短網址被訪問的次數,以提供後續分析(例如點擊次數等)作為使用情況的洞察
Out of Scope
- 對使用者進行身份驗證和授權(例如,誰可以建立 URL 或存取某些分析)。
- URL 過期或被使用者刪除。
- 超越點擊次數的進階分析(例如地理追蹤或裝置類型)。
規模要求
每日活躍用戶數達 1 億 讀寫比 = 100: 1 資料保留5年 假設每天有 100 萬個寫入請求 假設每個條目大約 500 位元組
API Endpoints
POST /api/urls/shorten Request Body:
{
"longUrl": "http://example.com"
}
Response Body:
{
"shortUrl": "http://urlshort.ly/abcd"
}
GET /api/urls/{shortUrl}
Response Body:
{
"longUrl": "http://example.com"
}
High Level Design
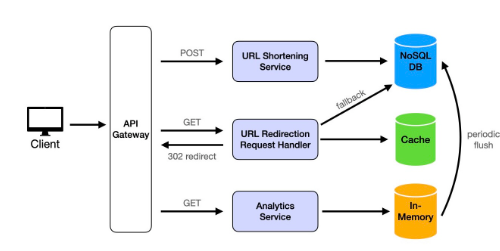
- URL縮短 使用者應該能夠輸入長 URL 並收到一個唯一的縮短別名。縮短的 URL 應採用緊湊的格式,包含英文字母和數字,以節省空間並確保唯一性。
URL 縮短的設計遵循基本的兩層架構,可以快速處理請求並擴展以處理大量請求:
- URL 縮短服務:後端接收請求,並負責建立和傳回縮短的 URL。它執行以下關鍵功能:
透過對 URL 進行編碼或使用雜湊技術來產生唯一的簡短別名以確保唯一性。 將長 URL 到短別名的對應儲存在資料庫中。 管理錯誤並確保每個短網址對所有使用者來說都是唯一的。
- 資料庫:使用高可用性資料庫(例如 DynamoDB 或 Cassandra)來保存長 URL 和短別名之間的對應。
- URL 重新導向 當使用者存取縮短的 URL 時,服務應以最少的延遲將他們無縫地重新導向到原始 URL。
URL 重新導向服務可確保存取縮短 URL 的使用者能夠快速重新導向至原始 URL,並將延遲降至最低。此設計著重高讀取吞吐量和低延遲,因為讀取流量將顯著高於 URL 建立流量。
URL 重新導向請求處理程序:接受具有縮短 URL 的 GET 請求,從快取或資料庫中檢索原始 URL,並使用302 Found狀態和標頭中的原始 URL進行回應Location,以實現無縫重定向。
快取層:為了減少延遲並卸載來自資料庫的讀取請求,我們實作了一個快取層(例如,Redis),將經常存取的 URL 映射儲存在記憶體中,使檢索幾乎是即時的。
資料庫:如果在快取中找不到 URL,系統將從資料庫中檢索它(以前為 URL 縮短實作)並更新快取以優化未來的請求。
- 連結分析 系統應該能夠追蹤每個縮短的 URL 的訪問次數,以了解連結的使用情況。
為了追蹤每個縮短網址的存取次數,我們推出了一項分析服務,用於即時統計和儲存存取事件。此設定能夠提供有用的連結使用模式洞察,並可靈活擴展以應對高流量。
分析服務:透過增加與短 URL 關聯的計數器來追蹤每次 URL 存取。此服務會記錄存取事件,並可在定期更新資料庫之前,使用輕量級記憶體計數器進行最佳化。
記憶體資料庫:為了實現高速存取統計,我們使用 Redis 等記憶體資料儲存來快取每個短 URL 的計數器。這樣可以實現即時追蹤,並減輕主資料庫的負載。
資料庫:分析服務會定期將記憶體中的計數器刷新到主資料庫,以確保存取計數的持久性儲存。
深入探討
創建的短網址ID最需要考量到的兩個元素?
- 唯一性 避免發生唯一性的ID Mapping到不同的網址
- 短小性
短網址產生後要產生足夠短的網址且符合人性,才符合短網址產生器的初衷
短網址產生氣ID的總結:必須創造出足夠短足夠唯一的短網址
該採用哪些方法來創建短網址?
選項1: Hash Functions
- 這邊有三個選手可以選擇
- MD5 雖然他很快就能產生128bit,但太容易碰撞了
- SHA256 他會產生256bit => 64字元大小的ID,太不切實際了
- Double Hashing or Longer Hashes 可以減少碰撞,但產出的ID依然太長
選項 2:UUID
UUIDv4依賴隨機性,並提供較大的 ID 空間(122 位元) UUIDv1使用時間戳記和機器的 MAC 位址來確保唯一性
選項 3:Snowflake ID
將時間戳記、機器ID和序號組合成64位元ID
選項 4:機器 ID + 序號(選定的解決方案)
如果機器 ID 是A1且序號是0001,則 ID 可以是A10001 可以透過調整機器 ID 和序號的大小來控制長度,從而允許我們透過添加更多具有唯一前綴的分片(機器)來實現擴展。這確保了唯一的 ID,而無需使用冗長複雜的字串。
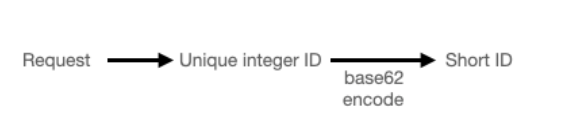
我們如何將唯一 ID 編碼為簡短、使用者友好的 URL?
總共三個選手
選手1: 十六進位(Base16) 字元:使用數字 0-9 和字母 af,共 16 個可能的字元。 缺點:對於 URL 縮短來說不夠緊湊;十六進制的 64 位元整數將產生 16 個字元的字串,這對於我們的需求來說太長了。
選手2: Base64 字元:使用 AZ、az、0-9、+、/ 和 =,共 64 個可能的字元。 缺點:使用特殊字元(+、/、=),這可能會導致 URL 出現問題並使打字更加困難。
選手3: Base62 字元:使用 AZ、az 和 0-9,共 62 個字元。 缺點:由於 62 不是 2 的冪,因此編碼/解碼過程稍微複雜一些,但可以控制。
最後選擇選手3: 62^6 ≈ 56 billion100 種可能性,且避免太少見的字元,這超出五年內 18 億個 URL 的需求。
Base62示範Demo:
import string
CHARS = string.ascii_lowercase + string.ascii_uppercase + string.digits
def base62_encode(num):
"""Encodes a number using Base62 encoding."""
if num == 0:
return CHARS[0]
encoding = ''
while num > 0:
num, remainder = divmod(num, 62)
encoding = CHARS[remainder] + encoding
return encoding
URL Shortener 系統設計重點
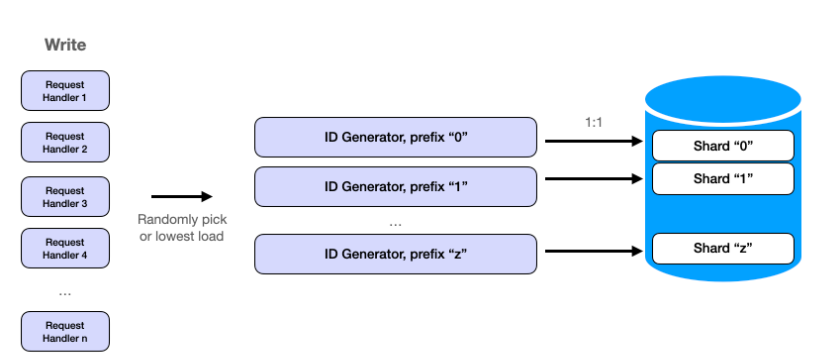
- Sharding & Data Management
每台機器負責不同的 shard → 維護更簡單(備份、索引、擴展可獨立進行,不影響全系統)。
讀取流程:
如果 cache miss,利用 短網址的 prefix 找到對應 shard → 查到 long URL。
Cache 也可以用相同 shard key 做分片,減少熱點。
- Scaling 策略
Request Handlers(請求處理器)
主要 I/O bound(處理 HTTP 請求、查 cache、維持 socket)。
需要 更多機器 來支撐高併發與低延遲。
URL Generation Service(ID 生成服務)
主要 CPU/I/O bound(生成 ID、寫 DB)。
每台效能相對高,數量需求較少。
Scaling 策略:
Request Handlers 可以獨立擴展,隨機挑選或按負載挑選一台 ID Generator 服務。
- Database 設計
適合使用 Cassandra、DynamoDB(天然支援水平擴展+分區)。
Schema:
short_url(含 Machine ID → 作為 shard key)
original_url
created_at
Replication:每個 shard 複製到多台機器,確保高可用與耐久性。
- ID 預先生成(Batch IDs)
問題:即時生成 ID 可能在高流量下成為瓶頸。
解法:預先批次生成 ID(系統啟動時或週期性),請求來時直接分配。
優點:
可應付突發流量
延遲更低(不用現場生成 ID)
缺點:
需額外基礎設施管理批次池
可能浪費(生成過多但沒用到)
✅ 總結一句話: URL Shortener 系統用 sharding + cache 分片 來加速查詢,Request Handlers 與 ID Generator 分開擴展以應付不同負載,Cassandra/DynamoDB 做水平擴展與高可用,並可考慮 批次預生成 ID 來避免高流量時的生成瓶頸。
